 English
English Deutsch
Deutsch 日本語
日本語 العربية
العربية Español
Español Português
Português Indonesia
Indonesia Tiếng Việt
Tiếng Việt 中文
中文
통계적 차익거래 이해하기: 수익성 있는 트레이딩으로 가는 길 6월 21, 2023 – Posted in: Arbitrage Software, cryptoarbitrage software – Tags: arbitrage software, forex arbitrage, statistical arbitrage, statistical arbitrage bot, statistical arbitrage software
통계적 차익거래(Statistical Arbitrage)는 흔히 “스탯 아브(Stat Arb)”라고 불리며, 헤지펀드와 프로프 트레이딩 회사에서 널리 활용되는 대표적인 퀀트 트레이딩 전략입니다. 이 전략의 핵심 개념은 서로 연관된 금융상품 간에 존재하는 가격 비효율성을 활용하는 것입니다. 통계적 차익거래를 사용하는 트레이더들은 복잡한 수학적 모델을 기반으로 거래 기회를 식별하며, 이로 인해 해당 전략은 알고리즘 트레이딩의 한 분야로 분류됩니다.
통계적 차익거래의 기원
통계적 차익거래는 1980년대 월가의 정량 분석가, 이른바 ‘퀀트(Quants)’들에 의해 처음 개발되었습니다. 초기에는 주식 시장에서 활용되었으며, 두 종목 간의 가격 차이가 장기적으로 평균으로 회귀하는 특성을 나타내는 공적분(Cointegration)을 기준으로 주식 쌍을 선정했습니다. 이후 이 전략은 발전을 거듭하며 외환(Forex) 시장과 암호화폐 시장 등 다양한 금융 시장으로 확장되었습니다.
핵심 원리
통계적 차익거래는 평균 회귀(Mean Reversion) 원리와 대수의 법칙에 기반합니다. 과거에 높은 상관관계를 보였던 금융상품들의 상대 가격은 시간이 지나면 다시 평균 수준으로 돌아온다는 가정이 핵심입니다. 통계적 차익거래는 이러한 상관관계를 가진 자산들의 가격이 역사적 평균에서 벗어났을 때 발생하는 괴리를 수익 기회로 활용합니다.
예를 들어, 역사적으로 함께 움직여 온 두 주식이 있다고 가정해 보겠습니다. 만약 한 종목은 상승하고 다른 종목은 하락하여 가격이 벌어졌다면, 통계적 차익거래 트레이더는 상대적으로 과도하게 상승한 종목을 공매도하고 하락한 종목을 매수하여, 두 종목 간의 가격 차이(스프레드)가 다시 수렴할 것에 베팅합니다.
스프레드(Spread)란 무엇인가
통계적 차익거래에서 ‘스프레드’란 일반적으로 서로 연관된 두 금융상품 간의 가격 차이 또는 괴리를 의미합니다. 이는 두 주식일 수도 있고, 선물 계약, 외환 통화쌍, 또는 암호화폐 토큰일 수도 있습니다.
대표적인 예가 페어 트레이딩(pair trading)입니다. 과거에 공적분 관계에 있던 두 자산의 스프레드가 역사적 평균에서 크게 벗어나면, 이는 거래 기회를 의미합니다.
스프레드가 과도하게 확대되었다면 한 자산은 고평가, 다른 자산은 저평가되었음을 시사합니다. 이 경우 고평가된 자산을 매도(또는 공매도)하고 저평가된 자산을 매수합니다. 반대로 스프레드가 지나치게 축소되면 그 반대의 포지션을 취합니다.
통계적 차익거래에서는 스프레드가 장기 평균을 중심으로 움직이는 평균 회귀 성향을 가진다고 가정합니다. 트레이더들은 스프레드가 평균에서 크게 이탈했을 때 다시 평균으로 돌아올 것으로 기대하고 그 과정에서 수익을 창출합니다.
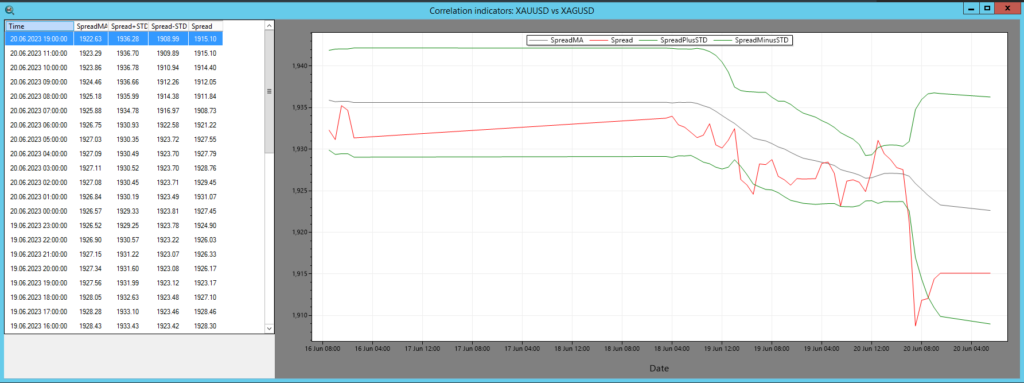
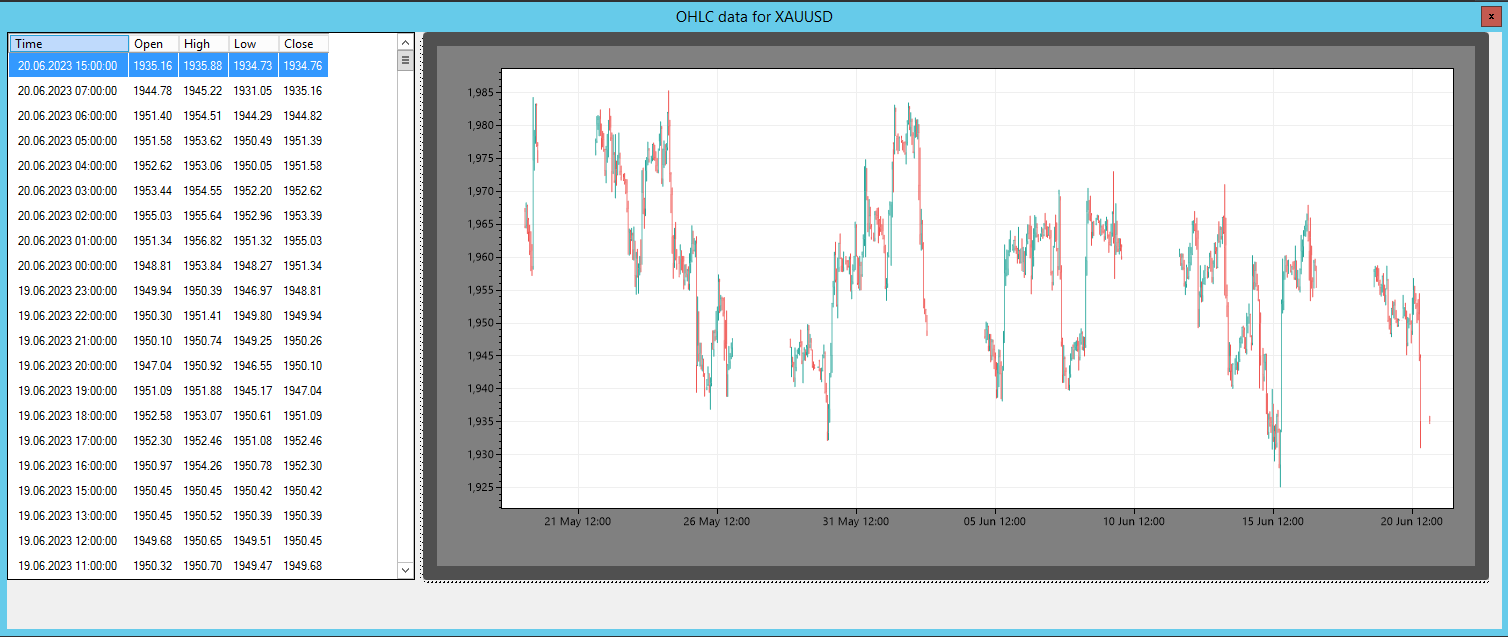
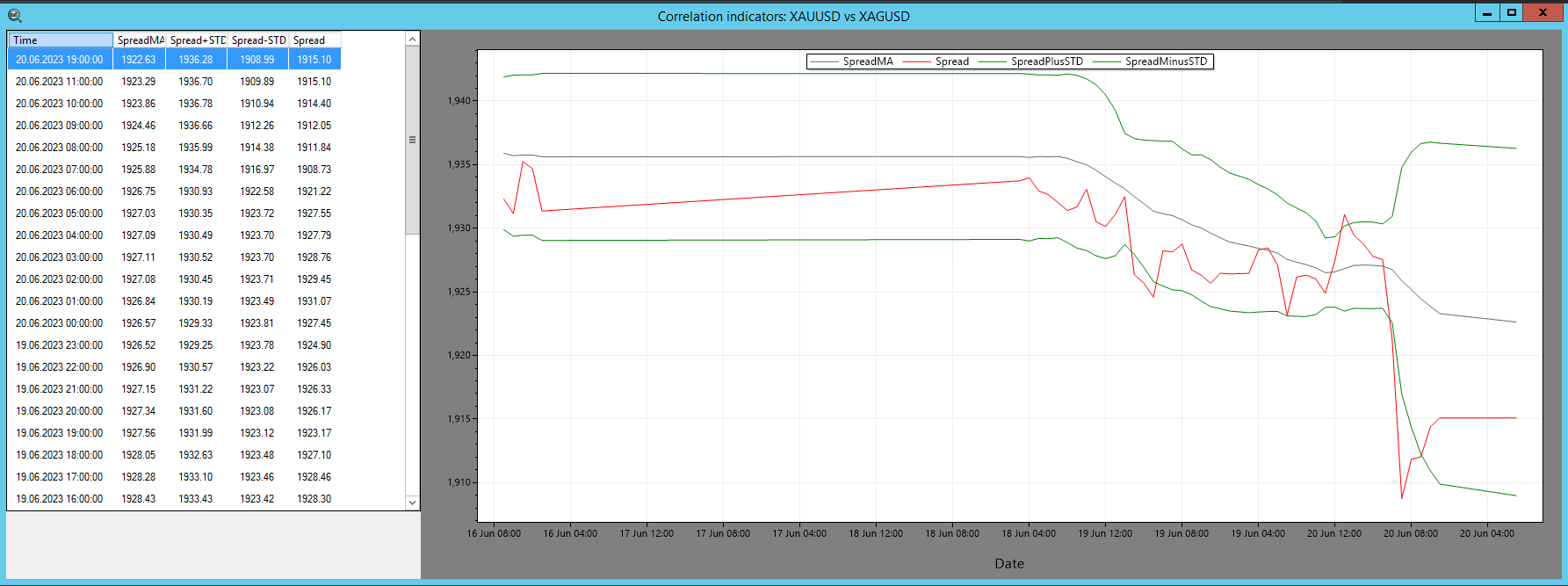
그림 1 – SharpTrader™ 스프레드 지표
SharpTrader™ 차익거래 소프트웨어에서는 스프레드 지표를 활용하여 두 자산 간의 상관관계를 시각적으로 표시합니다. 해당 지표의 계산에는 다음 요소들이 포함됩니다.
- 스프레드: 두 자산 가격 간의 수치적 차이
- SpreadMA: 지정된 기간(pi_SpreadMA_Period) 동안의 스프레드 이동평균
- STD(표준편차): SpreadMA 대비 스프레드의 표준편차
이러한 지표를 바탕으로 소프트웨어는 통계적 차익거래 이론에 따라 거래 진입 신호를 생성합니다.
상관관계 계산에 대한 간단한 이론

통계적 차익거래 – 상관관계 행렬
상관관계 행렬(correlation matrix)은 여러 변수 간의 상관계수를 표 형태로 나타낸 것입니다. 각 값은 -1에서 1 사이의 범위를 가집니다.
상관계수가 1이면 완전한 양의 상관관계, -1이면 완전한 음의 상관관계를 의미하며, 0은 두 변수 간에 관계가 없음을 나타냅니다.
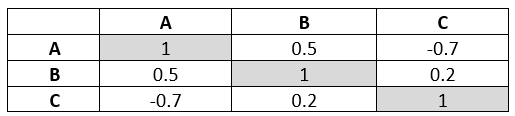
그림 2 – 상관관계 표 예시
이러한 상관관계 표는 금융 분야에서 자산 간 관계 분석, 포트폴리오 분산, 리스크 관리 등에 널리 활용됩니다.
통계적 차익거래 전략의 구현
통계적 차익거래의 구현은 매우 복잡하며, 고급 통계 도구, 고속 컴퓨팅 시스템, 그리고 정교한 알고리즘을 필요로 합니다. 일반적인 과정은 다음과 같습니다.
- 페어 선정: 공적분 테스트 등 통계적 방법을 통해 역사적으로 상관관계가 높은 자산 쌍을 식별
- 임계값 설정: 가격 괴리를 판단하기 위한 상·하한선 설정
- 거래 실행: 저성과 자산을 매수하고 고성과 자산을 공매도
- 거래 종료: 스프레드가 평균으로 회귀하면 포지션 청산
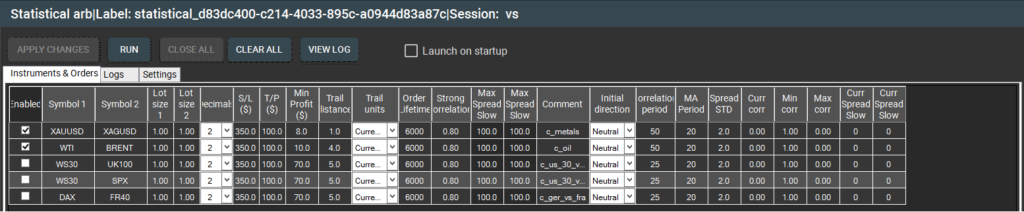
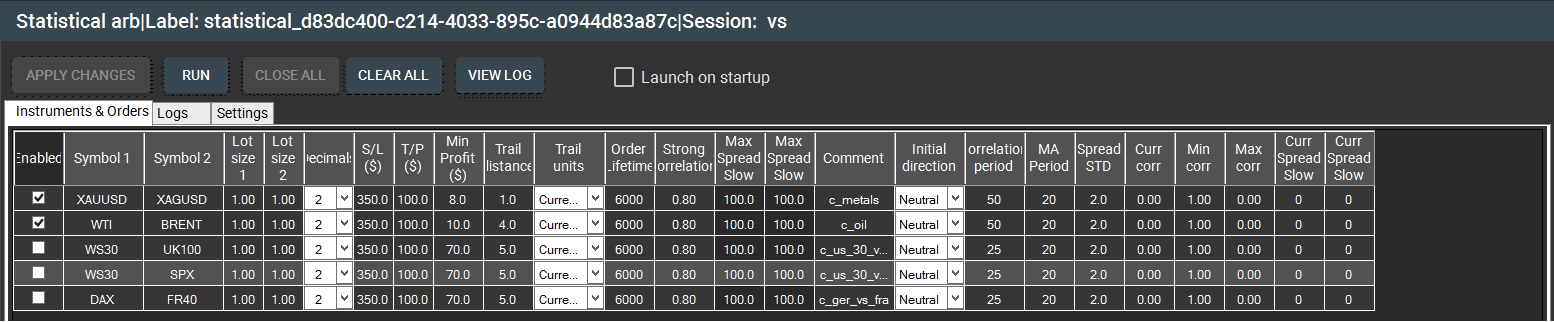
그림 3 – SharpTrader™ 통계적 차익거래 ‘Instruments & Orders’ 창
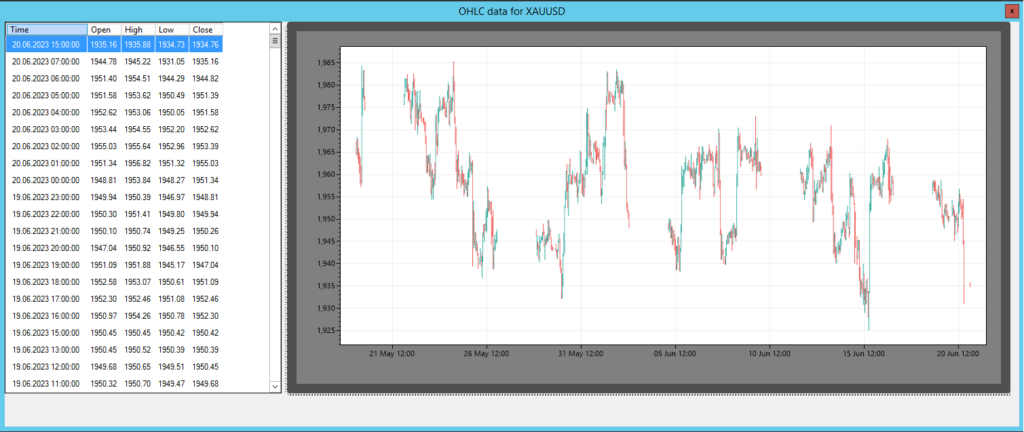
그림 4 – SharpTrader™ 통계적 차익거래 시세 및 그래프
위험 요소와 한계
다른 모든 트레이딩 전략과 마찬가지로 통계적 차익거래에도 위험이 존재합니다. 가장 큰 위험 중 하나는 ‘모델 리스크’로, 수학적 모델이 잘못된 가정에 기반할 가능성을 의미합니다. 또한 가격 비효율성은 밀리초 단위로 사라질 수 있기 때문에, 전략의 성공은 매우 빠른 실행 속도에 크게 의존합니다.
통계적 차익거래의 미래
금융 시장이 점점 더 효율적이고 자동화됨에 따라, 통계적 차익거래의 미래는 더욱 정교한 알고리즘, 머신러닝, 인공지능(AI)에 달려 있습니다. 기술 혁신의 속도가 빨라질수록 통계적 차익거래 역시 지속적으로 진화할 것입니다.
결론적으로, 통계적 차익거래는 복잡한 수학 모델과 초고속 실행에 의존하는 고급 트레이딩 방식입니다. 도전과 위험이 존재하지만, 적절히 구현될 경우 안정적이고 상대적으로 낮은 리스크의 수익을 추구할 수 있는 매력적인 전략으로 남아 있습니다.
